
AI gives weak answers when the source material behind it is unclear, outdated, duplicated, or poorly structured.
The model may sound confident. The wording may be clean. But if the AI is pulling from messy documents, vague policies, old reports, conflicting notes, or poorly labelled files, the answer will often be weak.
That is why many AI problems are not really AI problems at first. They are source material problems.
For business teams, this matters because AI assistants, internal search tools, knowledge base chatbots, and reporting workflows all depend on the quality of the material they retrieve. If the source base is messy, the AI has to build an answer from messy evidence.
Quick answer
AI gives weak answers when source material is outdated, duplicated, unclear, poorly labelled, or missing ownership. The model may sound confident, but retrieval depends on what it can find and how well that material is structured. Better answers usually start with a cleaner source base: current documents, clear metadata, review dates, access rules, and a way to trace answers back to approved sources.
Who this guide is for
This guide is for teams using AI search, chat, retrieval, or internal knowledge tools and wondering why the answers remain vague, inconsistent, or hard to trust.
It is especially relevant if you are dealing with:
- AI answers cite old or superseded files
- Different prompts produce different answers to the same operational question
- No one is sure which documents are approved, current, internal, or public
It is less relevant if:
- Your source material is already governed, reviewed, and structured, and the problem is mainly model selection or interface design
Key takeaways
- Quick answer: AI tools give weak answers when they cannot find, read, rank, or trust the right source material.
- Better prompting can improve wording, but it cannot fix outdated, duplicated, vague, or conflicting source material.
- The practical fix is cleaner source material, better metadata, defined source boundaries, retrieval rules, QA tests, source traceability, and human review.
Use the right guide for the problem
This guide owns the diagnosis question: why are the AI answers weak? Use it when the symptom is weak, vague, outdated, inconsistent, or hard-to-check answers. If the diagnosis points to source quality, the next step is usually a source inventory, cleanup pass, metadata structure, retrieval rules, and answer QA.
| Problem | Best next page |
|---|---|
| AI gives vague or inconsistent answers | This guide |
| Documents need cleanup before retrieval | How to prepare documents for AI retrieval |
| You need an internal retrieval environment | AI-ready knowledge environment |
| You need implementation support | Traceable Evidence Workflow Support |
What this diagnosis leads to
If the problem is source quality, the next step is usually a source inventory, cleanup pass, metadata structure, retrieval rules, and answer QA. If the problem is system design, the next step is a controlled AI-ready knowledge environment. If the documents themselves are not ready, start with how to prepare documents for AI retrieval.
What good looks like
| Weak setup | Stronger setup |
|---|---|
| AI searches a folder full of old and current files | Retrieval uses approved sources with current, superseded, draft, and archived status labels |
| Documents have vague names and no owner | Each source has a clear title, owner, review date, audience, and replacement rule |
| Answers sound polished but cannot be checked | Answers include source references that a reviewer can inspect |
| Internal and public material are mixed | Access rules separate internal, public, sensitive, and draft material |
Where this fits in the wider workflow
| Workflow stage | What happens |
|---|---|
| Input | Policies, reports, procedures, FAQs, internal notes, spreadsheets, and knowledge base documents |
| Structure | Source IDs, metadata, current-status labels, ownership, access rules, and retrieval-ready sections |
| Review | Human source checks, answer testing, governance review, and update rules |
| Output | More reliable AI answers, traceable responses, internal search results, and knowledge workflows |
Questions this guide answers
- Why is source material helpful when prompting AI?
- Why does AI make up sources?
- Is AI a source?
- Can AI provide reliable sources?
- Why does source quality matter for AI answers?
Why source material shapes AI answers
Source material is the information an AI system uses to answer a question.
What source material means in an AI system
In a business setting, source material can include policy documents, standard operating procedures, PDFs, reports, spreadsheets, help centre articles, product pages, sales decks, research notes, meeting transcripts, customer support scripts, internal wikis, databases, and archived files.
A retrieval-based AI system does not simply know which of these sources is current, approved, or relevant. It needs a structured way to find the right material and ignore the wrong material.
That is where many teams run into problems. They upload a folder of documents and expect useful answers. But the folder contains old drafts, duplicate files, mixed audiences, missing dates, and unclear ownership. The AI then turns that disorder into a fluent answer.
How AI uses source material to answer a question
Many business AI systems use retrieval-augmented generation, often called RAG. Google Cloud describes retrieval-augmented generation as a way to connect models to external information, including fresh, private, or specialised data, so responses can be more context-aware.
A simple RAG workflow looks like this:
1. A user asks a question. 2. The system searches a knowledge base. 3. It retrieves relevant pieces of source material. 4. The AI model writes an answer using that retrieved context.
OpenAI's retrieval documentation describes semantic search as a way to surface similar results from your data, even when there are few exact keyword matches. That search step is critical. If the retrieval layer pulls weak source material, the model starts from weak evidence.
Why messy material creates weak answers
A weak answer often starts before the model writes anything. The system retrieves the wrong source, an old source, or a vague source.
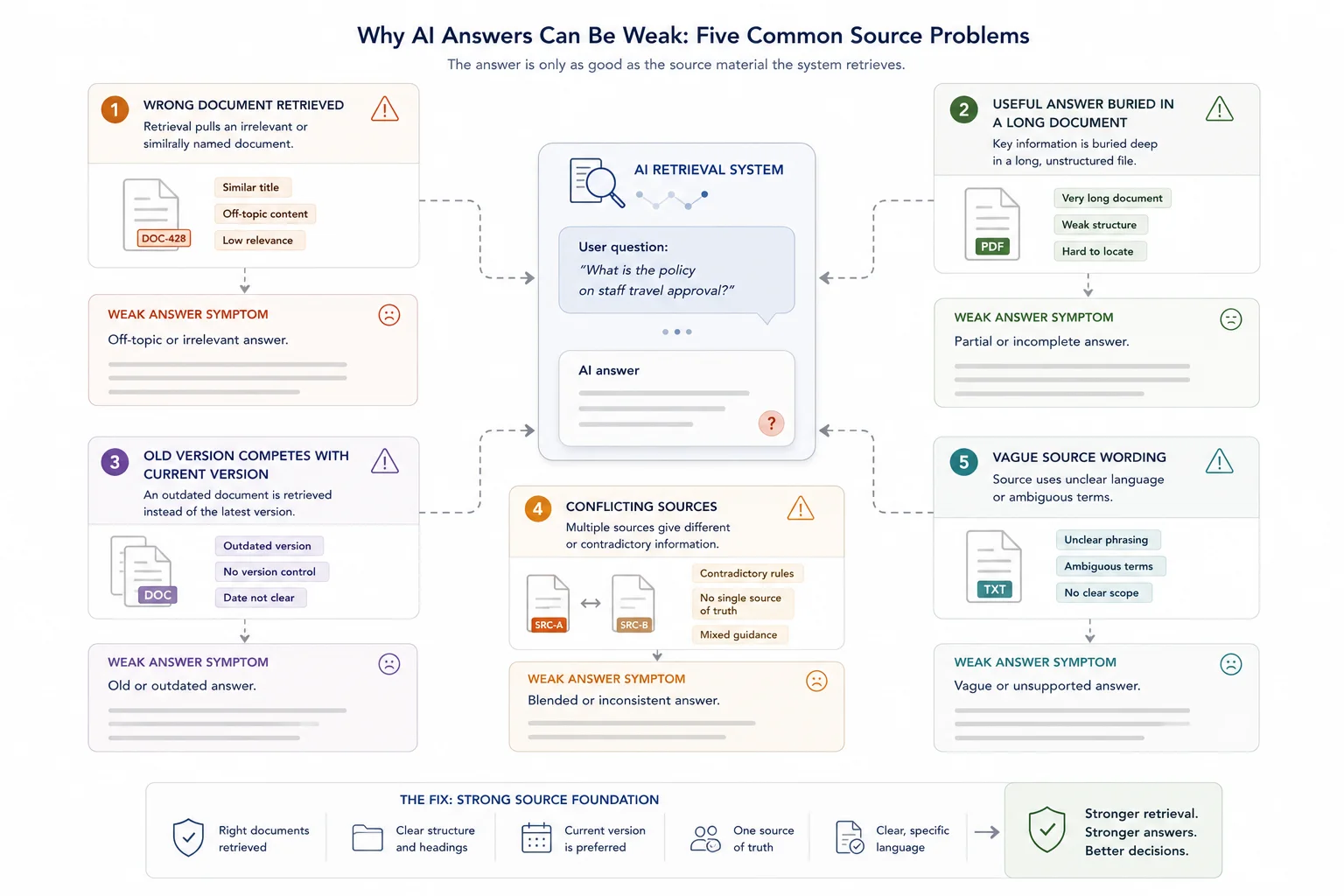
The AI retrieves the wrong document
A question about client onboarding might retrieve an employee onboarding checklist, a customer onboarding SOP, a sales onboarding deck, a project onboarding template, an old client onboarding process, or a meeting transcript where onboarding was discussed.
Those documents may use similar language. But they do not serve the same purpose. If the source material is not clearly labelled, the AI has no reliable way to know which document should carry the most weight.
This is why metadata matters. The system needs to know what each source is, who it is for, whether it is approved, and whether it is still current.
The right document exists, but the useful answer is buried
Sometimes the correct source is in the knowledge base, but the answer still comes out weak. This often happens when the source document is too long, poorly structured, or full of mixed topics.
A human can scan a 40-page report and connect the important sections. An AI retrieval system may only pull a few chunks from that report. If the rule is in one section and the exception is in another, the final answer can miss the nuance.
A document can be accurate and still perform badly as AI source material.
Old versions compete with current versions
AI systems often struggle when old and new versions of the same content sit in the same retrieval pool. An old policy may use the same wording as the current policy. An expired pricing page may mention the same product. A previous SOP may look more detailed than the current one.
If the AI retrieves the old version, the answer may sound reasonable but still be wrong. The issue is not that the AI cannot write. The issue is that the source base does not clearly separate active material from archived material.
Conflicting sources force the AI to guess
Messy source bases often contain more than one truth. One document says refunds take five working days. Another says seven. A support article says customers can cancel online. An internal note says cancellations must go through an account manager.
If there is no clear source hierarchy, the AI may blend the two answers or choose the wrong one. The fix is not only better prompting. The fix is source governance.
Vague source material creates vague AI answers
AI tools often reflect the quality of the writing they are given.
If the source says: refunds are usually processed quickly unless there are special circumstances.
The AI may answer: refunds are generally handled quickly, although some cases may require further review.
That sounds fine, but it does not help the user. Clear source material gives the AI exact timeframes, categories, conditions, exceptions, escalation paths, and approval rules. Weak source material gives the AI room to guess.
Not every weak answer is a hallucination
Teams often call every bad AI answer a hallucination. Sometimes that is accurate. Often, the problem is more ordinary.
Different source problems create different answer problems
If the AI is inventing information, you need stronger grounding and answer QA. If the AI is answering from old, vague, or conflicting material, you need better source material. Both problems can produce bad answers, but they do not have the same fix.
Source problems and answer symptoms
| Source problem | What the AI answer looks like |
|---|---|
| The right source is missing | The AI guesses from related material |
| The source is outdated | The AI gives an old answer |
| The source is vague | The AI gives a vague answer |
| Sources conflict | The AI blends two rules |
| The document is too long | The AI misses the useful section |
| Metadata is missing | The AI cannot tell which version matters |
| Internal and public sources are mixed | The AI gives the wrong level of detail |
| Review rules are unclear | The AI answers when it should escalate |
What makes source material AI-ready
Source material is AI-ready when people and systems can find it, understand it, compare it, and trace it. That means the content is not just uploaded. It is structured.
This is why AI readiness is not only a writing task. It is also a Traceable Evidence Workflow Support, documentation, and governance task.
AI-ready source fields
| Field | Why it matters |
|---|---|
| Source ID | Gives each document or record a stable reference |
| Clear title | Shows what the source covers |
| Owner | Shows who is responsible for the content |
| Last reviewed date | Helps avoid old answers |
| Status | Marks approved, draft, archived, or under review |
| Audience | Separates internal, customer-facing, public, and restricted material |
| Source type | Labels policy, SOP, FAQ, report, transcript, spreadsheet, or note |
| Replacement rule | Shows whether the source replaces an older version |
Define what the AI is allowed to use
A useful AI knowledge base should not treat every uploaded file as equal. Before building an assistant, define which sources are approved, excluded, archived, internal only, public-facing, restricted, under review, and higher priority when sources conflict.
A better AI workflow starts before the AI tool. It moves from source inventory to cleanup, metadata, approved source library, retrieval rules, AI assistant, human review, answer QA, and update cycle. The assistant should sit on top of a controlled knowledge base, not a messy folder.
Better prompting will not fix messy evidence
Prompting is useful. It can help control tone, format, answer length, citation behaviour, and escalation rules.
But prompting cannot reliably fix bad source material. If five documents disagree, the prompt does not magically know which one is current. If the answer is not in the knowledge base, the prompt cannot create a trustworthy source. If internal notes and public content are mixed together, the prompt cannot always know which audience the answer is meant for.
A better prompt can make a weak answer sound cleaner. It cannot turn messy evidence into a reliable knowledge system.
How to clean source material for better AI answers
Before changing tools or building a chatbot, review the source base.
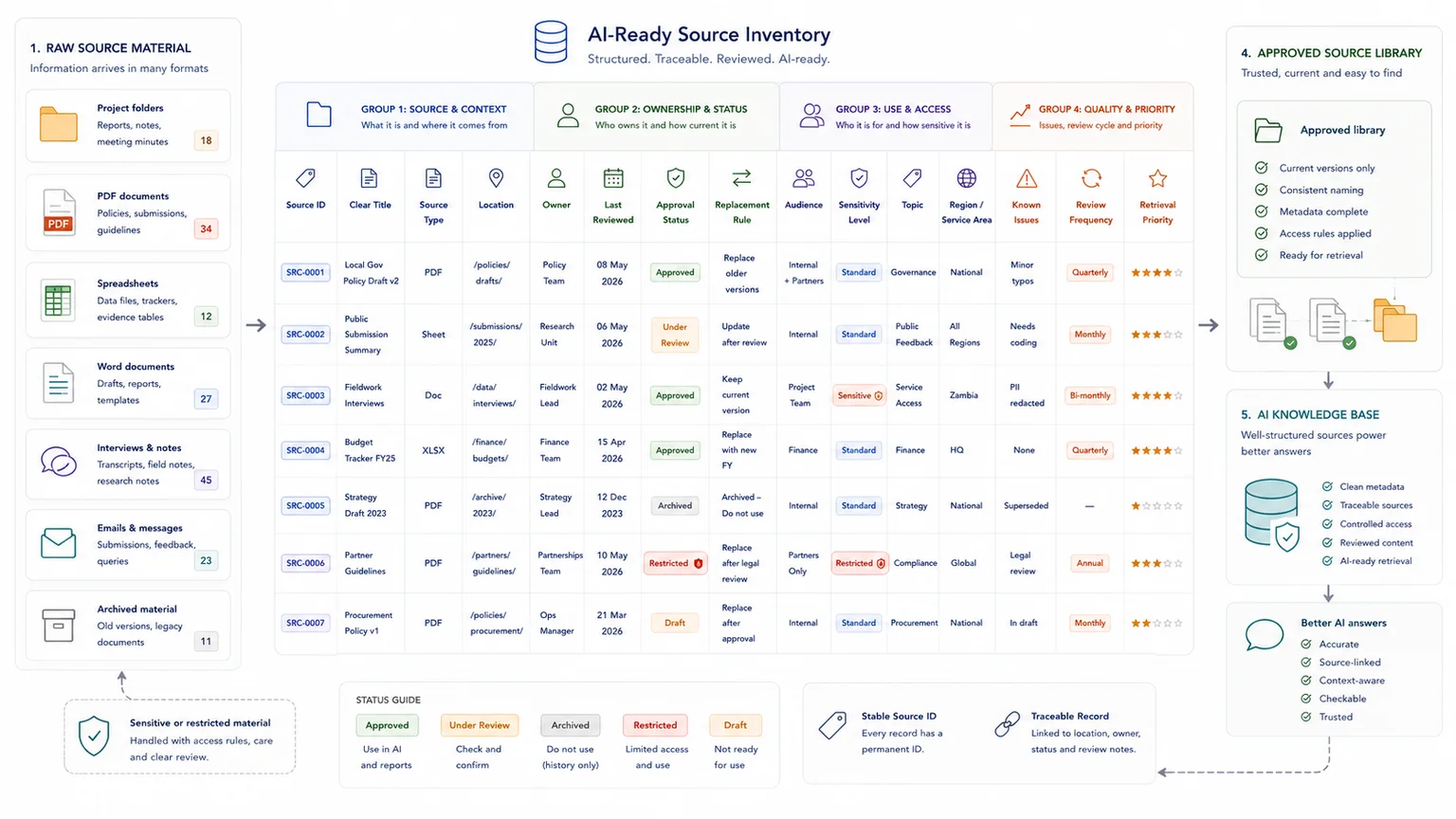
Create a source inventory
Start by listing the material the AI could use. Include documents, reports, PDFs, help articles, spreadsheets, databases, transcripts, SOPs, internal notes, and archived files.
A basic inventory should capture source name, location, owner, topic, status, audience, source type, last reviewed date, known issues, and replacement source.
Separate approved material from working material
Not every file should be available to the AI. Separate approved sources, draft sources, archived sources, internal-only sources, public-facing sources, restricted sources, and sources needing review.
This prevents the AI from treating a brainstorm, a transcript, an outdated report, and an approved policy as equal evidence.
Remove duplicates and archive old versions
Duplicates are one of the fastest ways to weaken AI answers. If the system retrieves the wrong duplicate, the answer may be based on old or incomplete information.
Archives can still be useful. They should not sit in the same active retrieval pool as current source material.
Rewrite vague sources into answer-ready sections
AI-ready source material should answer real questions clearly.
Weak source: the team should check whether the client is eligible before proceeding.
Better source: a client is eligible for onboarding when the contract is signed, billing details are complete, and the account owner has confirmed the start date. If any of these items are missing, the onboarding request should remain in pending status.
The better version gives the AI a rule, conditions, and an action.
Add metadata before ingestion
Metadata helps the retrieval system filter and rank sources. Useful metadata includes owner, topic, source type, approval status, audience, region, product or service area, last reviewed date, replacement rule, sensitivity level, and review frequency.
Without metadata, the AI is forced to rely heavily on text similarity. With metadata, it has more context for deciding what to use.
Define escalation rules
Some questions should not be answered automatically. The AI should escalate when sources conflict, no approved source exists, the source is outdated, the question is high-risk, the answer needs human approval, the source is under review, the system cannot trace the answer, or the user asks for a decision outside the AI's role.
NIST's AI Risk Management Framework focuses on managing AI risks to individuals, organisations, and society. For internal AI systems, that points to a practical lesson: reliable AI needs governance, review, and accountability around the system, not just a model connected to files.
Test whether source material is the problem
Use real questions. Test the system against the source base, not only against how polished the answer sounds.
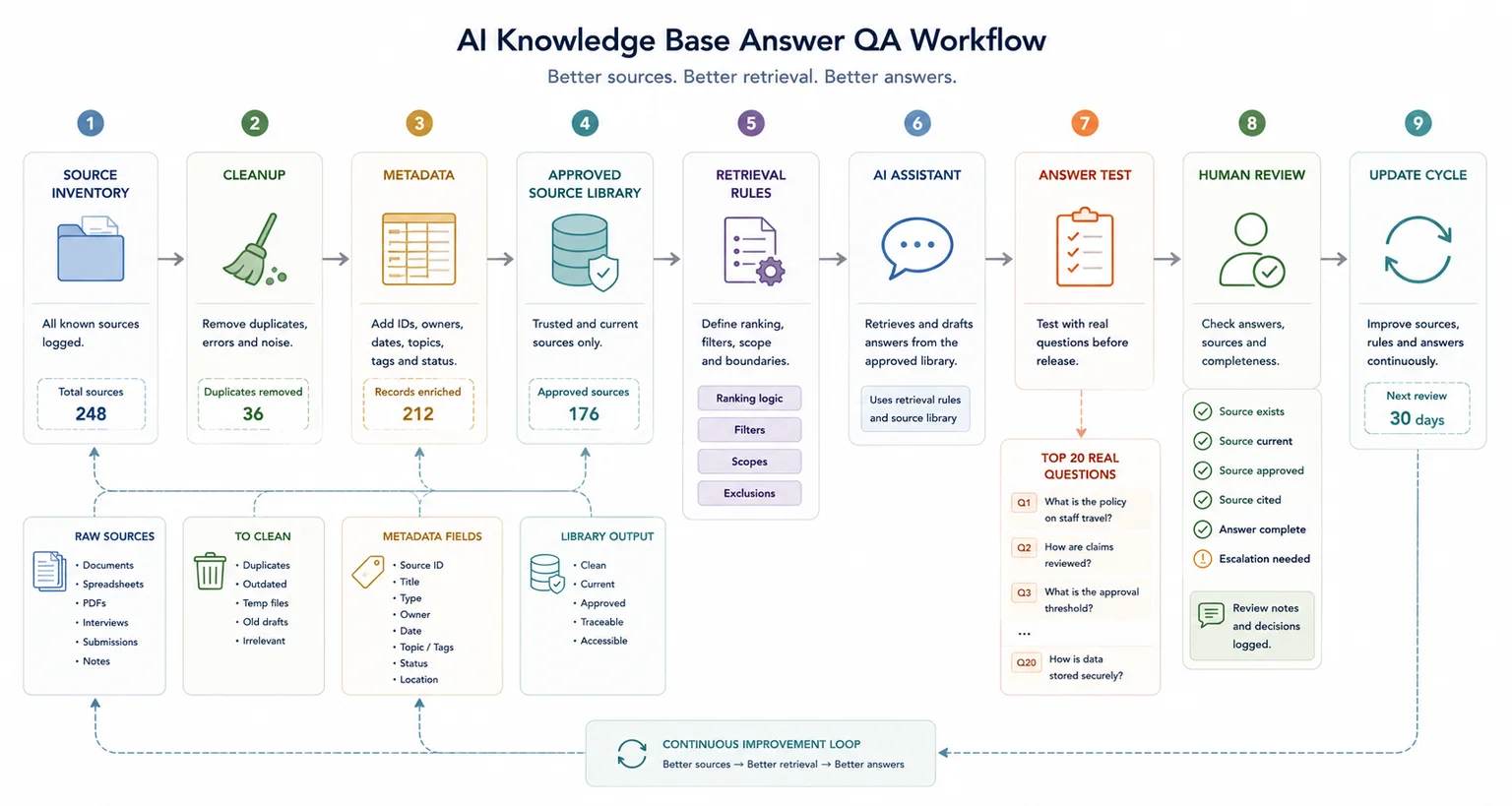
Run the top 20 real questions
Take the top 20 questions your team, clients, customers, or stakeholders ask most often. Run each one through the AI system, then check the answer against the source base.
For every weak answer, ask whether the right source existed, whether it was approved, whether it was current, whether it was easy to retrieve, whether another source contradicted it, whether the answer was complete in one place, whether the wording was too vague, whether the AI cited or traced the answer properly, and whether the question should have been escalated.
If repeated searching, checking, and weak retrieval are already costing the team time, you can model the cost of repeated searching, checking, and weak retrieval before rebuilding the source base.
Know when you need better source material instead of a better model
A better model can help when the task needs stronger reasoning, better formatting, clearer writing, or more consistent behaviour.
Better source material should come first when the AI gives old answers, cites the wrong source, mixes internal and public information, different teams disagree on the correct answer, documents have no owners or review dates, the answer exists but is buried, the AI gives vague answers to clear operational questions, or source traceability is weak.
Changing the model can hide these problems for a while. It does not fix the knowledge base.
Why source traceability matters
For business AI systems, it is not enough for an answer to sound right. You need to know where the answer came from.
Source traceability helps teams check which document supported the answer, whether the source was approved, when it was last reviewed, whether it has been replaced, whether the AI used internal or public-facing material, and whether the answer should have been escalated.
This is especially important for evidence-heavy work, reporting, policy interpretation, customer support, and internal decision-making.
Related guides
These adjacent guides are useful when this workflow needs a tighter next step: source register, South Africa AI policy, source-linked evidence table. Also see prepare documents for AI retrieval.
When a simple setup is enough
- The AI tool only answers low-risk internal questions
- The source set is small, current, and owned by one team
- Manual review is easy because every source can be checked quickly
When you need a more structured system
- Answers affect client work, public material, policy, or operations
- Source files are duplicated, outdated, or spread across several systems
- The team needs retrieval rules, review dates, access controls, and answer traceability
Common mistakes to avoid
Changing the prompt before checking the sources
Prompt wording can help, but it cannot make old, duplicated, or unclear documents trustworthy. Start by checking what the AI is being asked to retrieve from.
Treating all documents as equally current
AI retrieval can surface outdated material unless superseded files are marked or removed from the approved source set.
Skipping answer traceability
A fluent answer is not enough for serious use. The team should be able to see which source supported the answer and whether that source was approved.
Copyable AI source material diagnostic
Signs your AI problem may be a source material problem
| Sign | Present? |
|---|---|
| AI answers cite old or superseded files | |
| Different prompts produce conflicting answers | |
| The AI mixes internal and public information | |
| No one knows which document is current | |
| Source files have no owner or review date | |
| Answers sound polished but cannot be traced |
Related resources
Use these next if you need to move from the article into a related workflow, calculator, case study, or service.
- How to Prepare Documents for AI Retrieval - use this if the source files need cleanup
- AI-ready knowledge environment - use this if the problem is wider than document prep
- Traceable Evidence Workflow Support - use this if you need a structured internal retrieval setup
- Traceable Evidence Workflow Support - use this if AI needs to support a wider workflow
- Internal Knowledge Base ROI Calculator - use this to model repeated searching, checking, and weak retrieval
- How to stop losing source traceability - use this if answers need a stronger source trail
FAQ
Why does AI give weak answers even when I upload documents?
AI can still give weak answers if the uploaded documents are outdated, duplicated, vague, incomplete, or contradictory. Uploading files gives the AI access to material. It does not automatically make that material clean, current, or reliable.
How do I know if my AI problem is really a source material problem?
It is probably a source material problem if the AI gives different answers to the same question, cites old documents, mixes internal and public information, cannot show where an answer came from, or gives vague answers when the topic should have a clear rule.
What is an AI-ready knowledge base?
An AI-ready knowledge base is a structured source library built for retrieval. It includes approved sources, clear document status, metadata, ownership, review dates, source traceability, and rules for escalation.
Does RAG stop hallucinations?
RAG can reduce hallucination risk by grounding answers in retrieved source material. It does not remove the risk on its own. If the retrieved material is old, noisy, vague, or conflicting, the answer can still be weak.
Should we clean documents before building an AI assistant?
Yes. Source cleanup should happen before or alongside AI assistant development. If the source material is messy, the assistant will turn that mess into confident answers.
Can better prompting fix weak AI answers?
Better prompting can improve format, tone, and behaviour. It cannot reliably fix missing sources, outdated documents, duplicate files, or conflicting policies. Those problems need source cleanup and better knowledge base structure.
Why is source material helpful when prompting AI?
Source material gives the AI something specific to work from. A prompt can shape the answer, but it cannot make an unsupported answer reliable. For evidence-heavy work, approved source material helps the AI retrieve, compare, summarise and quote from the right documents instead of guessing around the question.
Is AI a source?
No. AI is not the source. The source is the document, dataset, interview, submission, report, case study or evidence record the answer is based on. AI can help retrieve or summarise source material, but the answer still needs to be checked against the underlying source.
Why does AI make up sources?
AI can make up sources when it is asked to support an answer without a controlled source base, retrieval rules or source-checking requirement. The safer workflow is to use approved source material and require answers to point back to source IDs, documents, rows, pages or quotes.
Planning an AI assistant or internal knowledge base?
AI gives weak answers when source material is messy because the system starts from weak evidence. The answer may sound polished, but polished wording is not the same as accuracy.
If your knowledge base contains old versions, duplicate files, vague notes, conflicting rules, mixed audiences, and missing metadata, the AI assistant will struggle.
Traceable Evidence Workflow Support can help turn scattered documents, spreadsheets, reports, and internal notes into a cleaner retrieval environment built around approved sources, metadata, traceability, and review rules.
Sources used in this guide
Traceable Evidence Workflow Support
Turn interviews, submissions, case studies, survey comments, documents, and field notes into coded evidence, quote banks, synthesis tables, findings, recommendations, and report-ready outputs.