
Source traceability becomes visible the moment a reviewer asks a simple question: where exactly does this line come from?
If the team cannot move quickly from a sentence, finding, or recommendation back to the source that supports it, review slows down and confidence drops. The problem is usually not one missing citation. It is a weak control layer underneath the workflow. If you need a rough diagnostic, you can test your source-traceability risk before rebuilding the control layer.
This guide is about that control layer: stable IDs, locators, evidence assets, and the route from source text to draft language.
Quick answer
Source traceability in evidence-heavy reports means every claim, figure, quote, finding, and recommendation can be checked against the material it came from. The practical fix is to use stable source IDs, locators, evidence registers, version control, and review notes from the start. This prevents late-stage cleanup and makes reports easier to defend when reviewers ask where a claim came from.
Who this guide is for
This guide is for report writers, researchers, evaluators, policy teams, and consultants who need evidence-heavy reports to stay checkable from source material through to final draft.
It is especially relevant if you are dealing with:
- Reviewers keep asking where claims, figures, or quotes came from
- Source references are rebuilt at the end of the project
- Several people are drafting, reviewing, or approving the same report
It is less relevant if:
- You are writing a low-risk internal note where formal source checks are not needed
Key takeaways
- Main principle: set the proof standard early and protect a separate evidence layer before coding, synthesis, and drafting begin.
- Operational consequence: stable IDs, locators, and named evidence assets make the route back to source usable under real delivery pressure.
- Review consequence: challenged claims can be checked quickly instead of forcing the team to rebuild the trail during sign-off.
What source traceability means
Source traceability is the control layer between evidence and final wording. It gives each source a stable reference, records the locator for the claim, and keeps the route from evidence to draft language visible.
Questions a traceable report should answer
In practice, traceability means being able to answer questions like these quickly:
- Which source supports this finding?
- Where exactly does that point appear?
- Has that source changed since the claim was written?
- Is the claim a direct quote, a coded summary, or an interpreted finding?
- Which theme, section, or recommendation does that evidence feed?
This matters in policy work, donor-funded research, evaluations, consultation analysis, and evidence-heavy reporting because source checks tend to come late, under pressure, and from people who were not part of the original coding or drafting process.
What good looks like
| Weak setup | Stronger setup |
|---|---|
| Claims are checked by searching old folders | Claims are linked to stable source IDs and locators |
| Quotes are copied without context | Quotes include speaker, source, date, and paragraph or timestamp |
| Figures are pasted into drafts manually | Figures have source, version, calculation note, and review status |
| Review notes sit in scattered comments | Review status and unresolved evidence questions are tracked in one place |
Where this fits in the wider workflow
| Workflow stage | What happens |
|---|---|
| Input | Reports, datasets, interview notes, submissions, transcripts, and source documents |
| Structure | Source register, stable IDs, locators, evidence extracts, claim IDs, and version rules |
| Review | Claim checks, quote checks, figure checks, reviewer notes, and approval status |
| Output | Traceable report drafts, evidence appendices, review logs, and defensible final reports |
Why source traceability gets lost
Most traceability failures come from a small number of workflow problems.
First, the source base is scattered. Files sit across folders, inboxes, forms, spreadsheets, tracked changes, and personal notes.
Second, there is no stable source ID or record ID.
Third, the team has not agreed on the unit of analysis. One analyst codes full interviews. Another codes quotes. A third writes theme notes straight into the draft.
Fourth, summaries get separated from the text that supports them.
Fifth, the report starts too early, before there is a proper middle layer between raw source and final prose.
That last point is one of the biggest causes of review pain. Without a usable middle layer, drafting becomes a second round of analysis under deadline pressure. If that sounds familiar, the adjacent guide on The Real Cost of Messy Evidence Workflows is worth reading alongside this one.
Steps overview
- Set the proof standard before coding or drafting begins
- Build a source register with stable IDs
- Set the unit of analysis before coding starts
- Separate raw source, working evidence, and draft language
- Add locators, quote fields, and review status
- Build a synthesis layer that still points back to source
- Link report sections to named evidence assets
- Run a traceability QA pass before review and sign-off
Use the steps below in order so the evidence trail stays intact before drafting pressure rises.
Decide what each output has to prove and how visible the source route needs to be before the work moves forward.
Before the team codes, summarises, or drafts, decide what each output has to prove and how visible the source route needs to be.
Ask what the workflow actually needs to support:
- a donor report
- a policy paper
- a consultation response
- a findings section
- a briefing note
- a synthesis memo
- a recommendation set
- a board or steering group pack
Then decide what level of proof each output needs. A broad descriptive point may need several consistent records. A contested claim may need a direct quote and an exact locator. A recommendation may need a visible line from source material to finding to implication.
This step keeps the workflow tied to a real delivery need. It also makes the rest of the structure easier to build, because you know what the evidence has to do once it reaches the writing stage.
Create one durable reference layer for every live source before detailed coding begins.
Every live source should have a stable reference before detailed coding starts.
At minimum, your source register should include:
- source ID
- source title or short name
- source type
- owner
- date
- version status
- storage location
- workstream or theme
- notes on quality, gaps, or restrictions
If the project includes repeated units such as interviews, submissions, case studies, comments, or site visits, each of those should also have its own record ID.
This is the layer that lets the team find material quickly and avoid confusion between the source itself and later evidence summaries. It also creates a cleaner bridge into database architecture and later AI retrieval prep if the system needs to support internal search or AI-assisted review later.
One rule that prevents later chaos
Keep source IDs stable even when file names change.
| Situation | What to do | Why |
|---|---|---|
| A PDF is renamed for clarity | Keep the same source ID | The ID should outlive file-name drift |
| A file is updated with substantive new content | Keep the source ID and update the version status | Reviewers can still follow the source history |
| A genuinely different source arrives | Assign a new source ID | The evidence trail stays unambiguous |
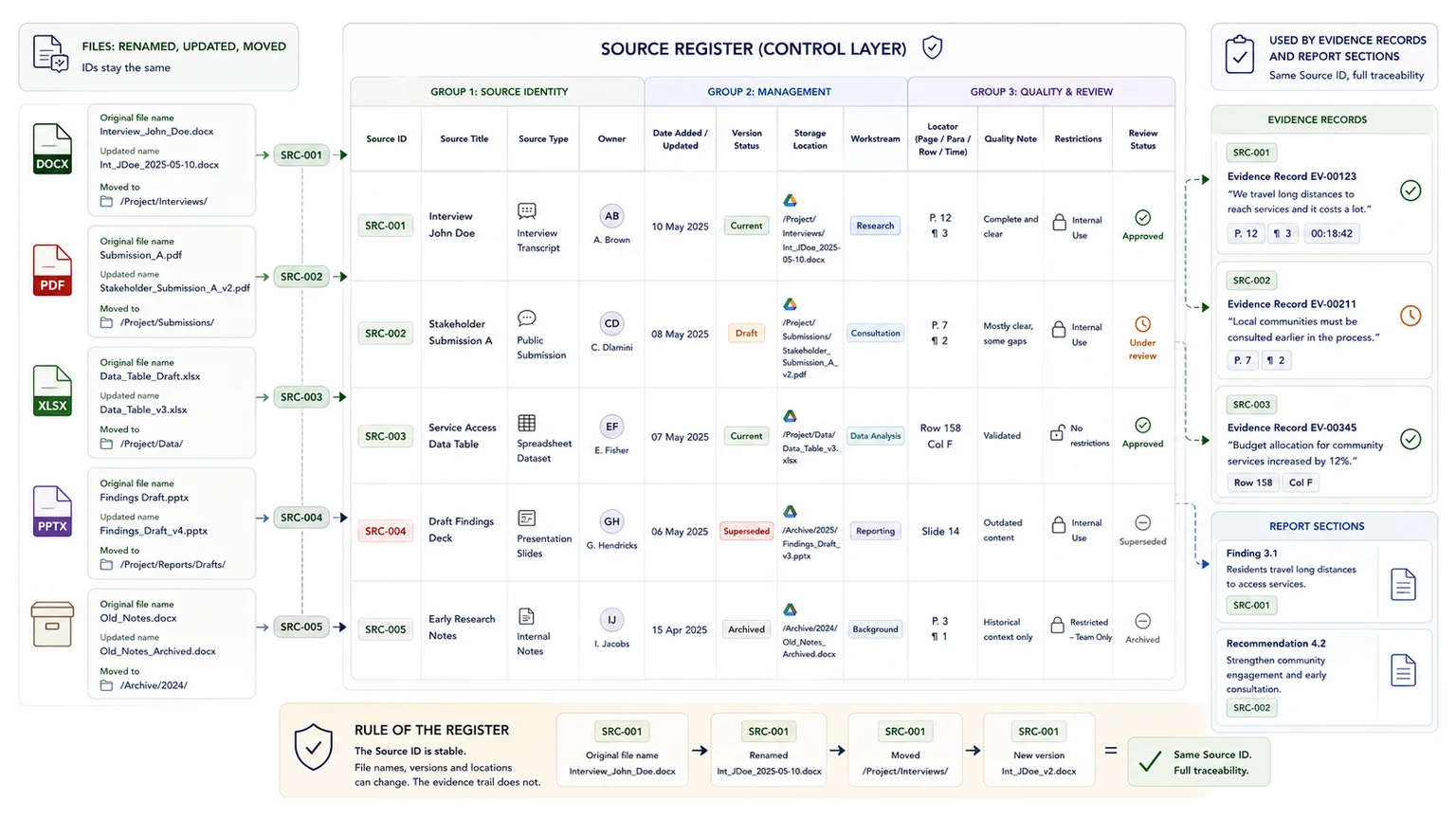
Decide what one evidence record actually is so the traceability chain stays consistent.
You need to decide what one evidence record actually is.
Depending on the project, it may be:
- one interview
- one interview segment
- one submission point
- one case study section
- one coded quote
- one survey free-text response
- one document paragraph
- one observation note
There is no universal answer, but there does need to be one answer for the project.
If one analyst codes at paragraph level and another codes whole documents, your synthesis layer becomes uneven and the traceability chain weakens. The problem is not only consistency. It is retrieval. Reviewers cannot move back to source cleanly when the record logic keeps shifting.
This matters especially in consultation and public input work. If that is your context, the guide on How to Synthesise Stakeholder Submissions Without Losing Source Traceability is a useful companion piece.
Protect the middle evidence layer so draft prose never becomes the only place the analysis lives.
The most important structural fix is to stop draft prose becoming the only place where the analysis lives.
Keep three distinct layers.
### Source layer
This is the raw material: transcripts, submissions, PDFs, spreadsheets, notes, source documents, and imported records.
### Evidence layer
This is where the material is cleaned, coded, summarised, tagged, and linked back to source through IDs and locators.
### Draft layer
This is where findings, sections, and recommendations are written.
When teams skip the middle layer, the draft becomes a mix of source notes, interpretation, half-tested claims, and writing in progress. That slows down review and weakens confidence in the final output.
A lot of the pressure described in How to Build Evidence Workflows for Reporting and Accountability comes from this exact problem.
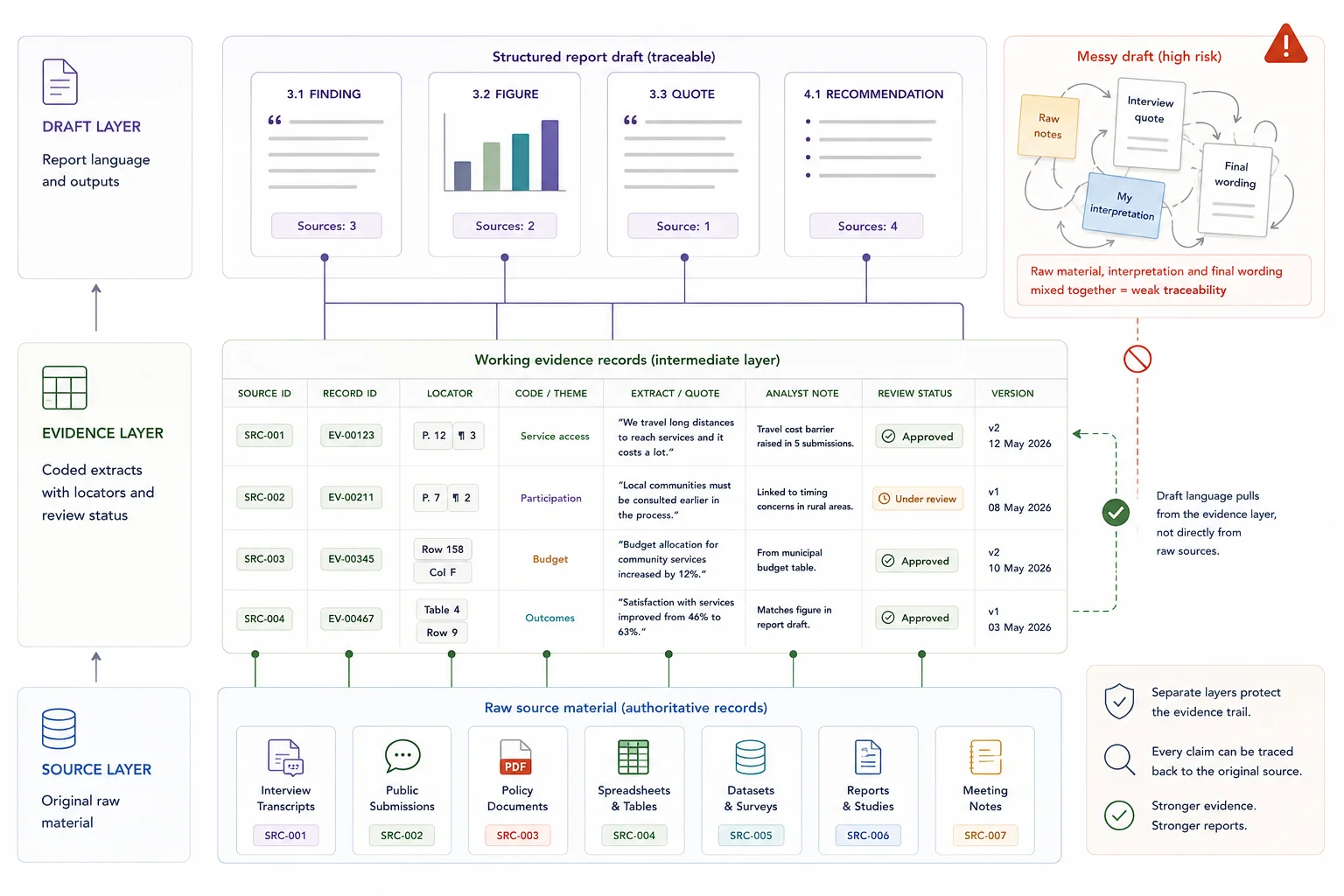
Give every evidence record enough context for somebody else to verify it without guesswork.
Every evidence record used in reporting should carry enough information for somebody else to verify it.
That usually means:
- source ID
- record ID
- theme or code
- short evidence summary
- direct quote or source excerpt where needed
- source locator
- analyst note
- review status
- linked report section if already known
Your locator format should match the source type:
- transcript: speaker and timestamp
- PDF: page and paragraph or section
- spreadsheet: sheet and row
- submission: submission ID and section
- note set: document name plus heading or bullet reference
- email: sender, date, subject, and quoted passage if needed
These fields are not admin for the sake of admin. They are what make later checking fast enough to be useful.
Make drafting easier by giving writers checked synthesis assets instead of loose notes and memory.
Writers should not have to work from loose notes and memory.
This article focuses on the control logic of that layer. Detailed method design belongs in the stakeholder-submissions and report-writing guides.
They should work from checked synthesis assets such as:
- theme summaries
- evidence tables
- framework matrices
- issue trackers
- finding sheets
- section-ready synthesis notes
A strong synthesis layer gives the writing team something stable to draft from. It also makes gaps easier to spot. If a finding is weak, the team can see it before it appears in the final report.
This is where data synthesis support overlaps directly with report writing workflows and decision-ready insight. Good synthesis does not flatten the evidence. It makes the evidence easier to use.
What this layer should contain
A strong synthesis table often includes:
| Field | Purpose |
|---|---|
| Draft finding | Gives the writer a report-ready summary to test |
| Supporting source IDs | Shows which evidence assets feed the point |
| Strongest supporting quote | Keeps the sharpest proof close at hand |
| Contrary or qualifying evidence | Prevents overclaiming and preserves caveats |
| Confidence or review status | Signals whether the finding is ready to use |
| Linked report section | Bridges synthesis and drafting |
Map each section to its evidence inputs before drafting gets busy.
Before drafting gets busy, create a simple report map.
A useful version can include:
- report section
- question the section must answer
- lead theme
- evidence asset feeding the section
- supporting source IDs
- writer
- reviewer
- status
This makes drafting faster because the writer knows where to pull from before opening the section.
It also makes review cleaner. If somebody questions a sentence, the team does not start searching blindly. They go to the section map, then to the synthesis asset, then to the evidence record, then to the source.
That bridge between evidence and writing is one of the most important parts of report writing on complex projects.
Test the evidence trail before the client, donor, or review panel does.
Do not wait for final review to discover weak locators, missing source IDs, or claims that no longer map cleanly to the source base.
Run a short QA pass first. Check whether:
- a reviewer can find the source behind a sampled claim in under two minutes
- the claim still matches what the source says
- summary tables include supporting IDs
- contrary or qualifying evidence is visible where it matters
- recommendations point back to named findings
- duplicate or superseded sources are still in use

What usually changes once the workflow is traceable
Once the traceability layer is stable, several downstream problems usually ease at the same time.
- writers spend less time searching backward through raw files
- reviewers can test claims faster and with more confidence
- quotes and summaries are less likely to drift from their source
- version changes are easier to spot before they affect the report
- recommendations stay more visibly anchored to evidence
Traceability improves both speed and defensibility
The gain is not only administrative neatness. It is operational. A traceable workflow makes the team faster because the evidence route already exists, and it makes the output more defensible because claims can be checked without rebuilding the trail from scratch.
Related guides
These adjacent guides are useful when this workflow needs a tighter next step: source register, source-linked evidence table, quote bank, South Africa AI policy. Also see reporting workflow.
When a simple setup is enough
- The report has few sources and one author
- Claims are descriptive and low risk
- A simple source list with page references is enough for review
When you need a more structured system
- The report uses many sources, datasets, interviews, or submissions
- Multiple reviewers need to verify the same claims
- The report may be challenged, audited, published, or used for decisions
Common mistakes to avoid
Leaving source tracking until the end
Late source cleanup is slow and risky. Capture source IDs and locators while extracting evidence, not after the report is drafted.
Using file names as source IDs
File names can change. Use a stable source ID that survives renaming, folder moves, and version updates.
Mixing evidence notes with draft language
Keep source notes, interpretation, and final wording separate enough that reviewers can see what changed between stages.
Copyable source register fields
Source register fields
| Field | Purpose |
|---|---|
| Source ID | Stable reference used across notes, analysis, and report drafts |
| Source title | Clear source name |
| Source type | Interview, report, dataset, submission, transcript, policy, or article |
| Author or owner | Person or organisation responsible for the source |
| Date | Publication, interview, submission, or review date |
| Locator | Page, paragraph, timestamp, row, quote ID, or section |
| Status | Current, superseded, draft, approved, or archived |
| Notes | Any limits, review comments, or context needed for use |
Related resources
Use these next if you need to move from the article into a related workflow, calculator, case study, or service.
- Evidence Insight Reporting Engine - use this if traceability needs to support reporting and decisions
- Traceable Evidence Workflow Support - use this if source material needs to be structured before reporting
- Data Use, Reporting & Communication Systems - use this if drafts need a stronger evidence trail
- Source Traceability Risk Checker - use this to check where traceability may break
- Evidence workflows for reporting - use this for the wider workflow around traceability
- Local government white paper evidence drafting review - use this to see the issue in a public-safe case study
Frequently asked questions about source traceability
Do we need specialist software first?
Not necessarily. Many teams can improve traceability with a cleaner source register, stable IDs, locators, review status, and a distinct synthesis layer before they change tools.
What usually causes source traceability to break?
The most common causes are scattered source material, no stable IDs, inconsistent record logic, missing locators, and drafting directly from raw files without a synthesis layer.
Do I need a database to improve source traceability?
No. A well-structured spreadsheet or shared evidence register can work well if it includes stable IDs, locators, review status, and a clear separation between source, evidence, and draft language.
What if the source base is already messy?
Start by stabilising IDs, naming the unit of analysis, and separating raw source from working evidence. That usually gives the team enough structure to improve the rest in stages.
Where does AI fit in this workflow?
AI is most useful after the source base, evidence layer, and locators are already stable. It is much less reliable as a substitute for weak traceability.
What is a report source?
A report source is the document, dataset, interview, submission, case study, record or evidence item that supports a claim in a report. In evidence-heavy work, each source should have a stable ID and locator so reviewers can check the claim quickly.
What does source report mean?
People may use "source report" to mean the report used as a source, or the source material behind a report. In an evidence workflow, the clearer term is source register: the controlled list of all source material used or reviewed.
Keep the evidence trail visible before the draft gets busy
Traceability is not admin polish. It is what makes review faster, findings safer, and recommendations easier to defend.
When the route back to source is already built, challenged claims can be checked quickly. When it is not, the team ends up rebuilding the trail under deadline pressure.
Traceable Evidence Workflow Support
Turn interviews, submissions, case studies, survey comments, documents, and field notes into coded evidence, quote banks, synthesis tables, findings, recommendations, and report-ready outputs.