
Stakeholder submission sets create a specific kind of analysis problem.
The team is usually dealing with unlike response channels, high-volume text, subgroup differences, public scrutiny, and later drafting pressure all at once. The job is not only to identify themes. It is to compare responses in a way that still holds up when someone asks where a finding came from. If this is already a live consultation or policy workflow, the Traceable Evidence Workflow Support is the commercial route for turning the method into a working system. If the immediate question is capacity, you can estimate how much submission volume your current setup can handle before changing the analysis method.
This guide shows how to run that process with the Framework Method: intake, source IDs, familiarisation, coding, matrixing, drafting inputs, and final QA.
Quick answer
Synthesising stakeholder submissions means turning public or stakeholder input into structured themes, issues, findings, response points, and reporting outputs. The process should preserve the link to original submissions while making patterns visible across respondents. A strong synthesis uses stable submission IDs, intake fields, coding rules, review steps, and clear outputs such as theme summaries, issue registers, response matrices, or reports.
Who this guide is for
This guide is for consultation teams, policy teams, public-sector projects, NGOs, researchers, and consultants handling stakeholder submissions or public feedback.
It is especially relevant if you are dealing with:
- Submissions arrive through several channels or formats
- The team needs to identify themes without losing the source trail
- Findings need to feed a response matrix, report, or decision process
It is less relevant if:
- You only have a few informal comments and do not need a formal synthesis or response record
Key takeaways
- What this page helps with: running a Framework Method workflow that keeps response channels, codebook logic, and matrix outputs visible under review.
- Who it is for: teams handling consultation responses, letters, survey comments, workshop records, or petitions that need to feed a defensible draft.
- What changes when it is done well: the submission set turns into a traceable matrix and drafting input instead of a pile of responses that has to be re-opened late.
What stakeholder submission synthesis means
Stakeholder submission synthesis is the step between raw feedback and usable reporting. It captures each submission, codes the content, compares issues across respondents, checks the source trail, and prepares outputs that can support decisions, responses, and public communication.
What good looks like
| Weak setup | Stronger setup |
|---|---|
| Submissions are read and summarised manually | Submissions are logged, assigned IDs, coded, and reviewed |
| Themes are broad and difficult to act on | Themes are specific enough to support responses and decisions |
| Quotes and claims lose source context | Each summary links back to the original submission |
| Final reporting starts from scratch | Reviewed synthesis outputs feed the response matrix and report |
Where this fits in the wider workflow
| Workflow stage | What happens |
|---|---|
| Input | Stakeholder submissions, survey responses, email comments, meeting notes, attachments, and feedback forms |
| Structure | Submission register, respondent types, themes, issue codes, source links, status fields, and review notes |
| Review | Coding review, theme review, source checks, redaction review, and approval |
| Output | Theme summaries, issue register, response matrix, public report, and decision support |
Before you start
This workflow is a strong fit when:
- the team is handling a large submission or consultation set
- multiple response channels are involved
- findings need to feed a report, briefing, recommendations, or policy draft
- reviewers will ask where a statement came from
- the work needs to hold up after staff handovers or review rounds
Before you begin, make sure you have:
- one folder or repository for the live source base
- a master catalogue or intake register
- stable source IDs and naming rules
- a decision on the unit of analysis for coding
- one owner for the working codebook and QA process
Why the Framework Method fits this workflow
The Framework Method is a well-established applied qualitative approach for working across multi-participant datasets through a matrix with rows as cases and columns as codes or themes Gale et al.. That is exactly why it fits stakeholder submissions so well: the team can compare across cases without losing the line back to each source. That method specificity is the point of this article. It is not the general evidence-workflow guide; it is the submission-synthesis playbook.
Practical guidance also stresses the control layer around the method itself: a master catalogue, stable source IDs, naming rules, version control, a research diary, and a maintained codebook ACI best-practice guide Cochrane Handbook.
Consultation-analysis guidance adds an operational warning: keep unlike response channels visible, record cleaning decisions, and explain campaign-response, subgroup, or weighting caveats rather than flattening everything into one pool Office for Students guide Nottinghamshire consultation guide.
On this site, the commercial pattern is already visible in live work. The South African Local Government White Paper workflow used source locators and quote fields inside a high-volume public-submission system. The UNICEF Zambia evidence workflow used quote-per-claim guardrails and spreadsheet traceability. The UNICEF Palestine situation analysis linked quotes, coded issues, service-access records, and theory-of-change layers so drafting could happen from organised evidence instead of raw notes.
Steps overview
- Separate the response channels and clarify the output
- Build the master catalogue and source IDs
- Clean the submission set before coding
- Read through the material and write early memos
- Draft the initial coding framework and codebook
- Pilot the coding and align the team
- Code the full set with traceable references
- Chart the data into a matrix and compare across cases
- Draft findings and QA the evidence trail
Define what you are producing and keep unlike response types visible before you start coding.
Before the team codes anything, decide what kind of submission exercise this is, what the output has to do, and which response channels must stay visible as distinct evidence streams.
Write down what the synthesis needs to produce. That may be a consultation report, board paper, thematic findings section, policy briefing, recommendation pack, or draft chapter input.
Then map the response channels feeding that output. Keep surveys, letters, petitions, workshops, meetings, and other channels visible as distinct types rather than collapsing everything into one blurred pool.
At this stage, answer:
- What output has to be produced?
- Which response channels feed it?
- What level of traceability will reviewers expect?
- Which subgroups matter for comparison?
- What weighting or caveat notes will need to be stated explicitly?
This step protects the logic of the whole workflow. Once very different response types are mixed without metadata, it becomes much harder to explain what the evidence actually shows.
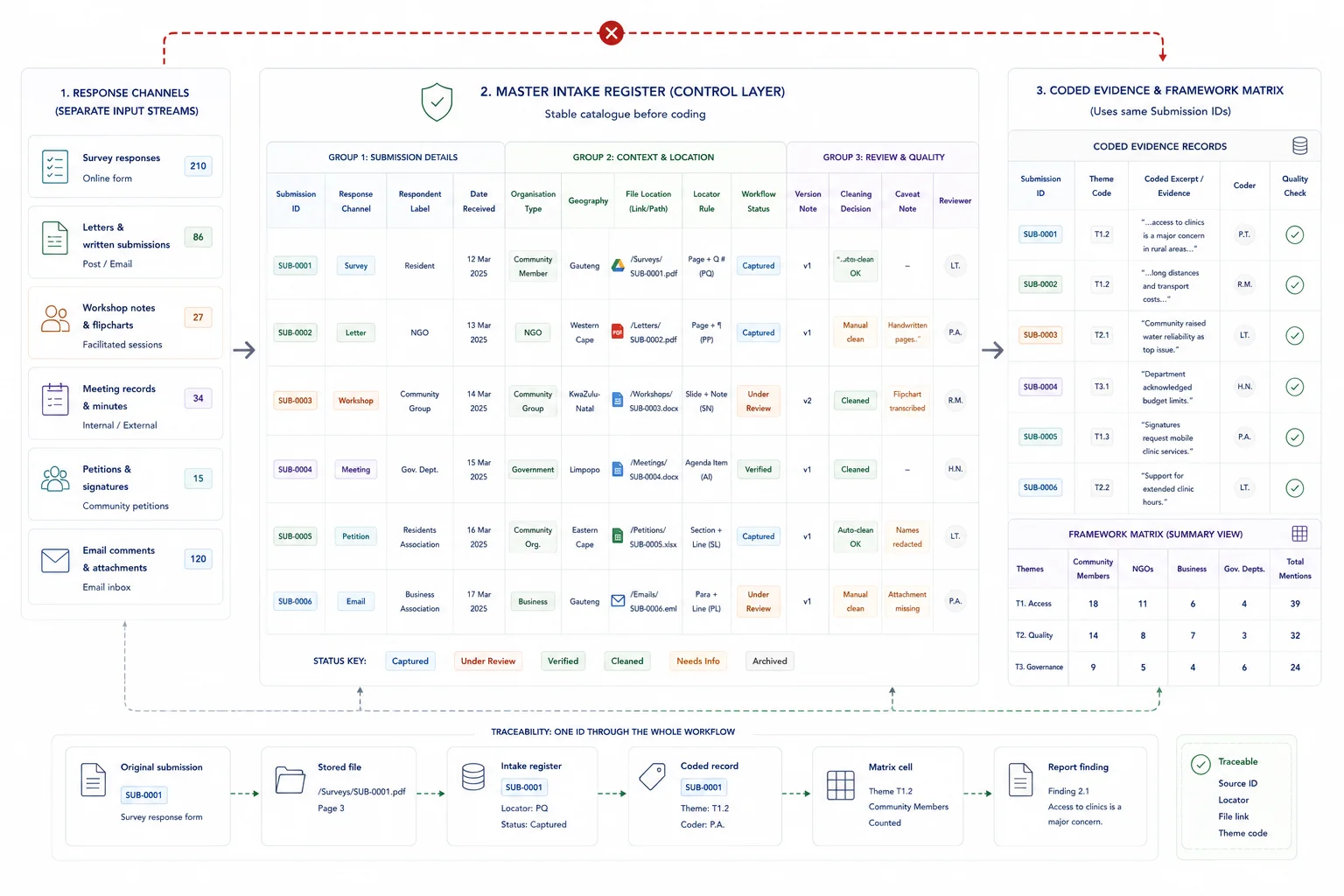
Create the control layer that lets every coded point travel back to a source.
Set up a master catalogue before full coding begins. This is the intake register for the live source base.
A compact register is easier to scan when the team is pressure-testing intake logic. The example below shows the kind of fields that keep unlike submission types visible and traceable from the start.
If the workflow will later need quote-level referencing, plan that now as well. A good setup reserves fields for excerpt references, page numbers, transcript numbers, or paragraph locators so the charting stage does not have to retrofit them.
This is also where stable naming rules, version control, and a research diary start to matter. They are not extra admin. They are the audit trail.
If you want to see this logic in live public-consultation work, the Local Government White Paper case study shows how quote fields, source locators, and taxonomy controls support later drafting and review.
Sample intake register fields
| Field | Why it matters | Example value |
|---|---|---|
| Source ID | Gives every record a stable reference for coding, charting, and QA | WS-LET-014 |
| Response channel | Keeps unlike evidence streams visible instead of blended too early | Letter |
| Respondent label | Shows who submitted the response or how it should be grouped | Provincial business chamber |
| Date received | Supports audit trail checks and reporting windows | 2026-02-11 |
| Organisation type or subgroup | Makes later comparison possible | Business association |
| Geography | Preserves comparison by place when it matters | Gauteng |
| File location | Returns the reviewer to the source quickly | /submissions/letters/WS-LET-014.pdf |
| Locator rule | Prepares the workflow for quote-level trace-back later | Page and paragraph |
| Status | Shows where the record sits in the workflow | Cleaned, ready for coding |
Remove weak records and obvious noise before they distort the coding work.
Before detailed analysis, clean the response set.
Check for:
- blank responses
- duplicate responses
- campaign or template responses where relevant
- broken files or incomplete records
- submissions logged twice under different names
- source files missing the metadata needed for later comparison
This step is also the moment to record the cleaning choices. If you remove blanks, duplicates, or invalid entries, keep that decision in the working notes and summary counts.
A controlled submission set saves time later because the team is not spending its coding hours on records that should have been filtered out at intake.
Use familiarisation and memoing to shape the coding framework before full coding begins.
Do not jump from intake straight into a giant coding pass.
Read a cross-section of the material first. Aim to cover different response channels, respondent types, and apparent positions. During that read-through, keep short memo notes on:
- recurring issues
- outlier concerns
- differences by respondent group
- language patterns worth preserving
- methodological concerns that could affect interpretation
- possible headings for the coding framework
This memoing stage matters because qualitative extraction is iterative rather than one-pass. Teams often need to move backwards and forwards between familiarisation, coding, and refinement before the framework settles.
The output of this step is not a finished theme set. It is a sharper working sense of what the submission set is really saying and what details need to be preserved later.
Turn the early read-through into a framework the team can apply consistently.
Now build the first working coding framework.
In submission work, the codebook is not just an analysis tool. It is part of the later reporting defence.
Start by listing the main topical categories that the output needs to answer. Then define the codebook fields for each code:
- code name
- short definition
- what belongs in the code
- what does not belong in the code
- any subgroup notes or qualifiers
- whether the code is descriptive, evaluative, or action-oriented
In consultation or submission work, a practical framework usually combines a priori structure with room for inductive refinement. That means the reporting questions and consultation themes may shape the starting columns, while the material itself still expands or sharpens the coding logic.
Keep version control tight here. Once the codebook starts changing, record what changed and why.
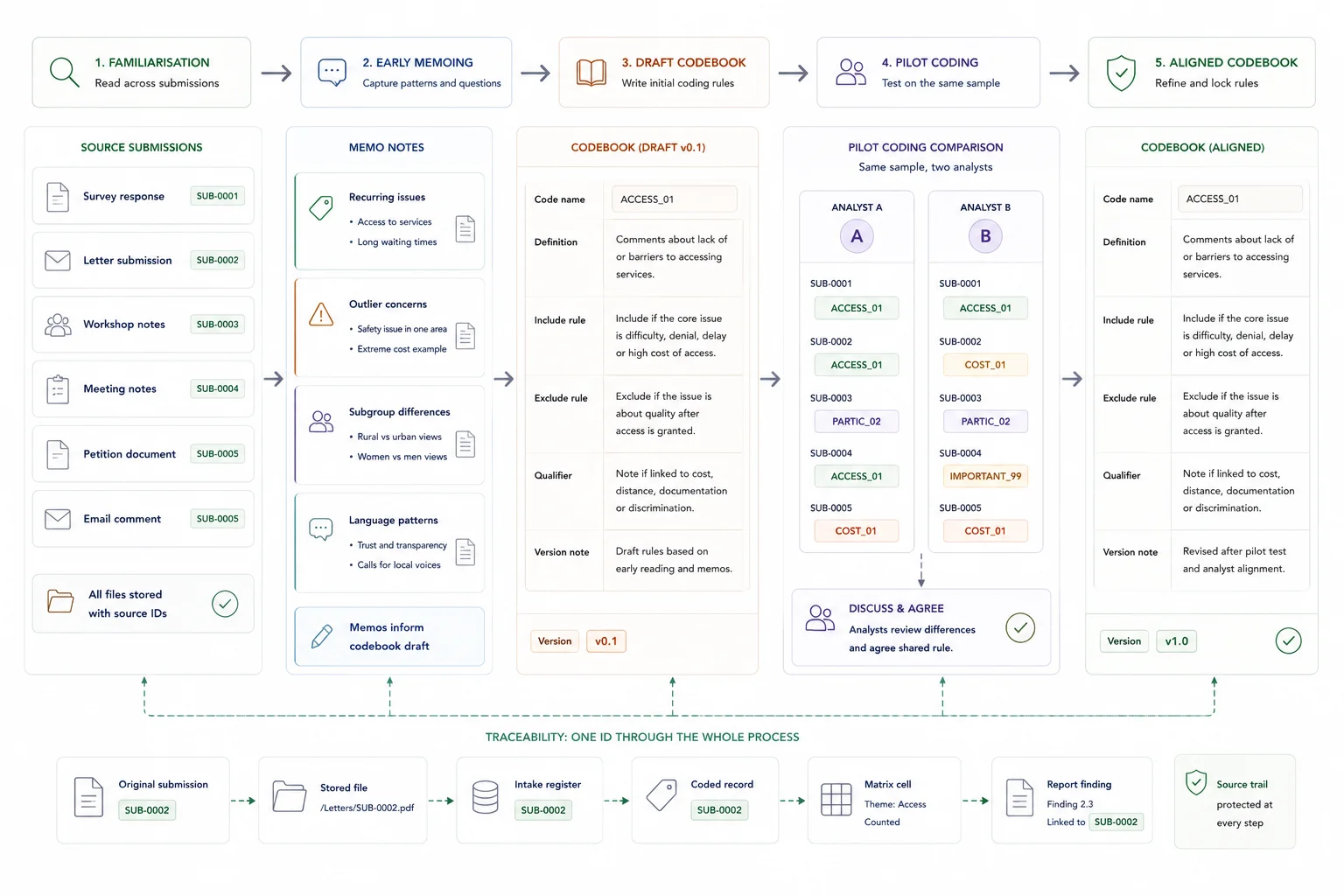
Test the framework on a sample before the full coding pass.
Run the framework on a sample first.
Pick a small set of responses that covers different channels or respondent types. Code them, compare the results, and check for:
- overlap between codes
- codes that are too broad or too narrow
- missing categories
- inconsistent treatment of the same issue
- uncertainty around what counts as enough evidence for a code
This is where inter-coder and intra-coder consistency checks help. The goal is not perfect statistical neatness. The goal is to expose drift early enough that the codebook can still be corrected.
At the end of this step, the team should have one agreed codebook version, a clearer sense of the matrix columns, and fewer surprises waiting inside the full submission set.
Apply the framework to the whole submission set while keeping the evidence trail intact.
Once the framework is stable enough, code the full set.
For each coded point, preserve the evidence reference that lets someone move back to the source later. Depending on the material, that may include transcript number, page, line, paragraph, response ID, or another source locator.
Also preserve contextual fields that matter later, such as response channel, geography, organisation type, stakeholder group, or any methodological note that helps explain the evidence.
This is where traceability becomes real. The coded record should not just say what theme appeared. It should say where it appeared and under what conditions.
The UNICEF Zambia workflow is a strong example of how quote-per-claim guardrails and structured traceability make later reporting faster and safer.
Turn coded material into a matrix that supports cross-case and subgroup comparison.
This is the core Framework Method move.
The matrix is where the submission set stops being a pile of responses and starts becoming a usable comparison structure. If the matrix is weak, the later draft will either flatten the differences or over-rely on vivid examples.
Build the matrix with rows as cases and columns as codes or themes. Then chart the coded material into the relevant cells using concise summaries, source references, and quote excerpts where needed.
The matrix is where the synthesis becomes usable. It lets the team compare:
- one respondent group against another
- one geography against another
- one response channel against another
- recurring concerns across the full dataset
- outlier positions worth keeping visible
Good charting is not copy-paste dumping. It is concise, source-linked summarising that preserves enough context to stop the evidence from flattening.
This same matrix logic also sits inside the UNICEF Palestine workflow, where coded issues, quotes, service-access patterns, and theory-of-change layers had to work together for fast drafting.
Mini framework matrix row
| Case | Channel | Code | Charted summary | Locator |
|---|---|---|---|---|
| WS-LET-014 | Letter | Service access barrier | Business chamber says rural applicants miss appointments because transport is expensive and routes are unreliable; requests mobile outreach support. | p. 3, paras. 2-3 |
| SUR-088 | Survey | Service access barrier | Respondent reports repeated missed visits because taxi costs and travel time make attendance unrealistic. | Q14 comment 088 |
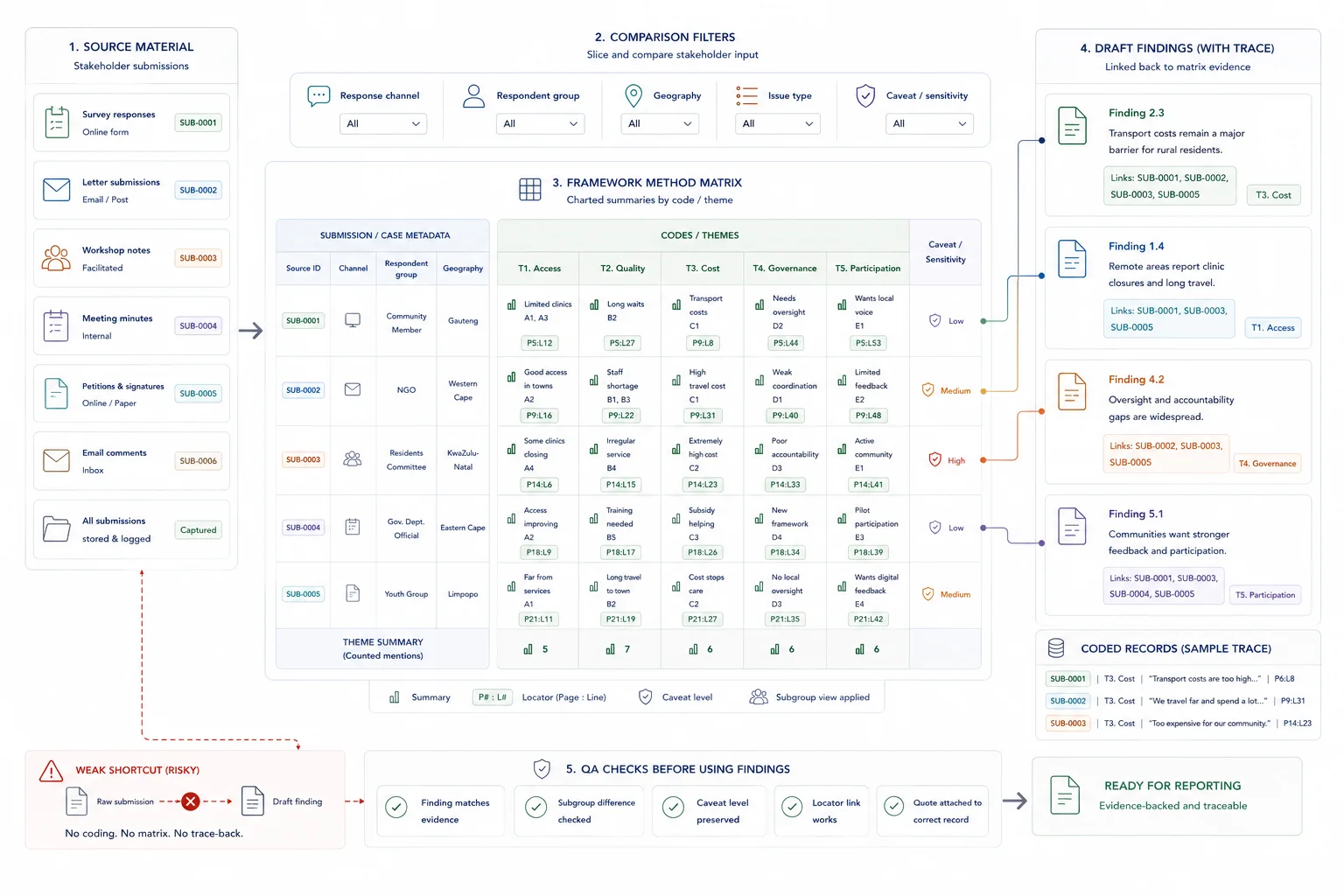
Write from the matrix, then check the route back to source before anything is signed off.
Drafting should happen from the matrix and coded evidence base, not from raw files.
At this stage, each finding or recommendation should be able to answer four questions:
- What does the pattern appear to be?
- Which coded evidence supports it?
- Which subgroup, channel, or context conditions matter?
- Where can a reviewer go to verify the point?
Run one final QA pass before the draft goes out. Check:
- whether the finding still matches the coded evidence
- whether any weighting or caveat note needs to be stated explicitly
- whether subgroup differences are described accurately
- whether the source locators still work
- whether quotations or paraphrases are still attached to the right records
This is where the workflow protects the report. If a reviewer challenges a claim, the team should be able to move straight back to the coded record and source reference rather than reopen the whole submission set.
If your team is still fixing these problems later in the writing cycle, How to Build Evidence Workflows for Reporting and Accountability is the broader systems view behind the same issue.
Related guides
These adjacent guides are useful when this workflow needs a tighter next step: source register, source traceability, findings-to-recommendations matrix, quote bank. Also see public consultation response matrix.
When a simple setup is enough
- Submission volume is low
- Respondents are few and issue areas are narrow
- One reviewer can read and verify the full set manually
When you need a more structured system
- Submissions are high volume or arrive in several formats
- Several analysts need to code or review the material
- The output must support a public response, decision record, or report
Common mistakes to avoid
Starting with themes before logging submissions
If the intake register is weak, the synthesis will be hard to check. Log the material before grouping it.
Letting one submission dominate the synthesis
A detailed submission can be useful, but synthesis should still show patterns across respondent groups and issue types.
Separating synthesis from response drafting
The synthesis should produce fields that can feed the response matrix, decision log, or report. Otherwise the team repeats the work later.
Copyable submission intake register
Submission intake register fields
| Field | Purpose |
|---|---|
| Submission ID | Stable reference for each submission |
| Respondent type | Individual, organisation, public body, business, NGO, or other group |
| Date received | Intake tracking |
| Channel | Email, survey, portal, meeting, or written submission |
| Main issue | First-pass issue summary |
| Theme | Coding category |
| Source link | Link to the original submission |
| Review status | Not started, coded, reviewed, or approved |
Related resources
Use these next if you need to move from the article into a related workflow, calculator, case study, or service.
- Traceable Evidence Workflow Support - use this if stakeholder submissions need a controlled review workflow
- Traceable Evidence Workflow Support - use this if submissions need coding and synthesis
- Traceable Evidence Workflow Support - use this if qualitative input needs to become findings
- Submission Analysis Capacity Calculator - use this to estimate review workload
- Local government white paper evidence drafting review - use this to see a related workflow
- What a public consultation response matrix should include - use this for the response stage after synthesis
FAQ
What is the Framework Method in qualitative analysis?
It is a structured approach that organises qualitative material into a matrix with rows as cases and columns as codes or themes, making cross-case comparison easier without losing the line back to source material Gale et al..
When is the Framework Method a good fit for stakeholder submissions?
It is a strong fit when the team needs to compare many responses across themes, subgroups, or channels and still preserve source traceability for drafting and review, especially when the work needs a matrix-backed audit trail Gale et al. ACI best-practice guide.
Should survey responses, letters, petitions, and meetings be analysed together?
They can be read against each other, but they should be recorded and reported as distinct response channels first. Mixing them too early weakens interpretation and later reporting Office for Students guide Nottinghamshire consultation guide.
What should the audit trail include?
At minimum, keep a master catalogue, stable source IDs, file naming rules, version notes, a controlled codebook, memo notes, and source locators for coded excerpts or quotes ACI best-practice guide Cochrane Handbook.
When should AI be added to this workflow?
After the catalogue, codebook, source IDs, and matrix logic are stable. AI works much better when it sits on top of an organised evidence base rather than a messy submission set, because trustworthy qualitative analysis depends on clear data-management steps and preserved context before tools are layered on top Bingham Cochrane Handbook.
What is a framework matrix for stakeholder submissions?
A framework matrix is a table that places cases or submissions in rows and codes or themes in columns. It helps the team compare issues across sources while keeping each point linked to the original submission.
How do you synthesise stakeholder submissions without losing source traceability?
Use a source register, stable submission IDs, a controlled codebook, a framework matrix and a QA pass before drafting. Each finding should link back to coded records and source locators.
A better stakeholder-submissions workflow starts before the report
A strong stakeholder-submissions workflow starts long before the drafting stage. By the time the report begins, the team should already have a catalogue, a stable codebook, a matrix, and a checked route back to source.
That is what makes the final output faster to write, easier to review, and safer to defend.
Sources used in this guide
Framework Method background and matrix structure.
Read sourceAudit trail controls including catalogues, codebooks, naming, and diaries.
Read sourceCleaning, coding framework, coding checks, subgroup analysis, and weighting caveats.
Read sourceAdvice on keeping response channels distinct during consultation analysis.
Read sourceIterative extraction and preserving contextual and methodological detail.
Read sourceFive-phase backbone and memoing logic.
Read sourceTraceable Evidence Workflow Support
Turn interviews, submissions, case studies, survey comments, documents, and field notes into coded evidence, quote banks, synthesis tables, findings, recommendations, and report-ready outputs.